こんにちは。最近蒸し暑いですね。
社内でサーバーサイド勉強会というのが週に1回開催されています。その場で、最近調べたMySQLとインデックスについて発表したのでせっかくなのでブログで記事にしておきます。
ここに含まれる情報は全てMySQL5.7/InnoDBでの情報ですので、最新のものとは事情が違う可能性がありますので注意してください。
インデックスとは?
データベースの検索処理の性能を向上させる方法の一つです。検索処理を行う事前に適切なインデックスをテーブルに対して付与しておくことで、検索処理が高速に動作します。
なぜ早くなるのか?
適切なインデックスが貼られていないテーブルに対して検索処理(SELECT ~)が走った場合、目的のデータを見るけるためにテーブル内の全データを上から順番に確認していく必要があります。ですが適切なインデックスが貼られている場合は、そのインデックス(=索引)を使って目的のデータを見つけることが素早くできるためです。
インデックス(=索引)が存在している場合、それに対応するBツリーインデックスというものが存在しています。(Bツリーインデックス以外のインデックスも世の中には存在しているようですがMySQLではBツリーインデックスを利用している為それに絞って書きます)
Bツリーインデックスとは B+Treeの木構造です。B+TreeはB-Treeと異なり末端の要素同士がLinkedListで繋がっている場合が多く、RDBMSでは要素を舐めていくときに高速に動作します。
B+木(英: B+ tree)は、キーを指定することで挿入・検索・削除が効率的に行える木構造の一種である。動的な階層型インデックスであり、各インデックスセグメント(「ブロック」などと呼ばれる。木構造におけるノードに相当)にはキー数の上限と下限がある。B+木はB木とは異なり、全てのレコードは木の最下層(葉ノード)に格納され、内部ノードにはキーのみが格納される。
Bツリーインデックスは以下の3種類のノードで構成され
- ルートノード
- Bツリーインデックスの頂点ノード
- ブランチノード
- 頂点でもなく末端でもないノード
- リーフノード
- 末端ノード。RowID(実データへのポインタのようなもの、セカンダリインデックスの場合)かまたはプライマリーキー(クラスタ化インデックスの場合)を持ちます
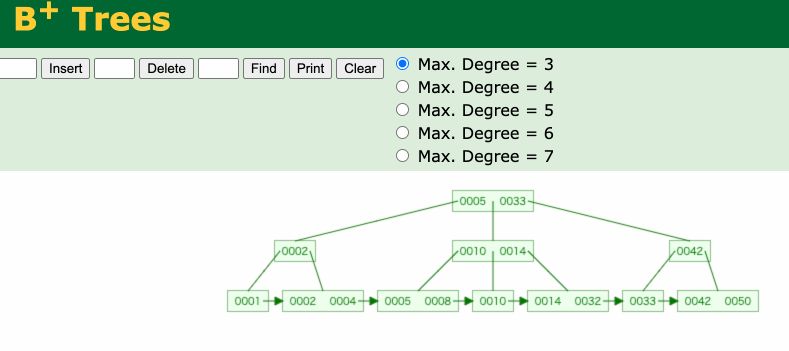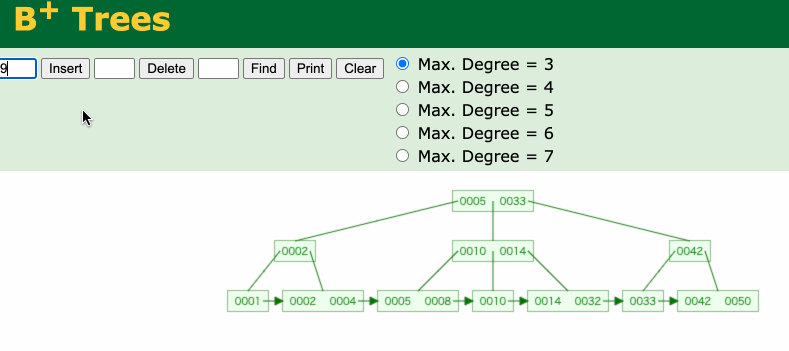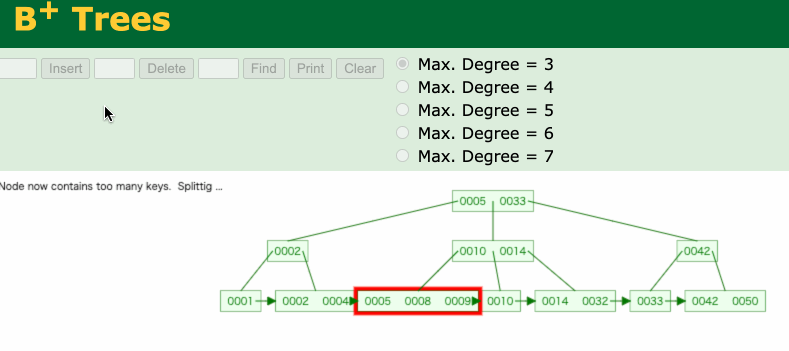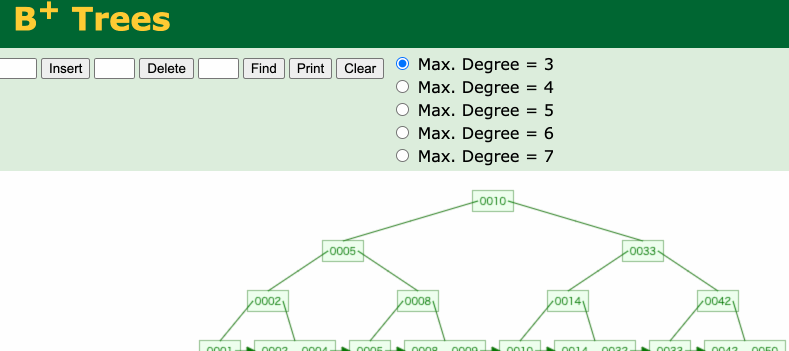
例えば数値型のカラムに対するインデックスが貼られている場合、Bツリーインデックスは以下のようになっています。

このBツリーインデックスで57で検索するとき、以下のようにルートノードブランチノード→リーフノードという順に巡回します。

最終的にリーフノードでRowIDまたはプライマリーキーを見つけ出し、RowIDの場合はRowIDをもとに実データにアクセスします。プライマリーキーの場合はプライマリーキーをもとにクラスタ化インデックスから検索し同様にRowIDを見つけ出し実データにアクセスします。
https://use-the-index-luke.com/ja/sql/anatomy/the-leaf-nodes

デメリット
インデックスを貼ることのデメリットに insert, update, deleteの処理を行う場合に処理コストがかかるという点があります。
Bツリーインデックスを最新の状態に変更する必要があるためです。しかし、最大でもBツリーインデックスをルート→リーフ→ルートという順番に処理が走る程度(時間計算量的には$\mathcal{O}(\log n)$)なのでインデックスを貼ることを気にするほどのコストではないと思っています
インデックスをどのカラムに貼ると効果的
インデックスは検索処理が行われてなおかつその検索処理を高速化するために存在しているので、そもそも検索処理で利用しないカラムには貼っても意味がありません。
なので一言で言うと、大量のデータの中からごく一部のデータを取得したい検索クエリが存在する場合に、カーディナリティが高く選択率が低くなるカラム群にインデックスを貼ることで関連す検索処理は大きく性能向上する可能性が高いです。
選択率は、現代のRDBMSでは5~10%程度未満になる条件が良いとされています
:::info カーディナリティ
先程の例で言うと性別のカーディナリティは2になる。他にも例えば1年間の日付なら1〜365なのでカーディナリティは365になる。カーディナリティが高いのは日付ということになる。
どういうときにインデックスが有効になるか
自分の環境で色々なパターンを試してみたので共有します
以下のような給与管理テーブルsalaries(約280万レコード)があるとします。

where句の条件に、単一インデックスのカラムが利用されているクエリ
select * from salaries where to_date ="1985-08-24"
上記のSQLを以下の2パターンで以下のSQLを実行した際の実行完了時間を比較しました。
- インデックス(
to_date)がある場合 - インデックスなしの場合
結果は以下の通りです。
- インデックス(
to_date)がある場合- 2.3ms
- インデックスなしの場合
- 2.78s
インデックスなしの場合に比べてインデックス有りの場合は実行速度が1000倍程度早区なることがわかりました
where句の条件に、複合インデックスのカラムが全て利用されているクエリ
上記パターンの複合インデックスバージョンで検証してみました。
select * from salaries where from_date ="1985-08-24" and emp_no="32536"
上記のSQLを以下の2パターンで以下のSQLを実行した際の実行完了時間を比較しました。
- 複合インデックス(
emp_no,from_date)がある場合 - インデックスなしの場合
結果は以下の通りです。
- 複合インデックス(
emp_no,from_date)がある場合- 1.7ms
- インデックスなしの場合
- 4.86s
インデックスなしの場合に比べて複合インデックス有りの場合は実行速度が4000倍程度早いことがわかりました
where句の条件に、複合インデックスのカラムが一部利用されているクエリ
上記パターンを少し変えてみて、複合インデックスのカラムが一部しかwhere句に書かれていない場合で検証しました。
複合インデックス(emp_no, from_date)が貼られている場合および複合インデックス(from_date, emp_no)が貼られている場合のそれぞれで、以下の2パターンでSQLを実行した際の実行完了速度および実行計画を比較しました。
select * from salaries where emp_no ="32536"select * from salaries where from_date ="1985-08-24"
結果は以下の通りです。
| where句 \ 複合インデックス | (emp_no, from_date) |
(from_date, emp_no) |
|---|---|---|
where emp_no ="32536" |
29.6ms | 16.6s |
where from_date ="1985-08-24" |
16.9s | 3.4ms |
複合インデックスの先頭に来ているカラムをwhere句に使った場合は使ってない場合に比べて1000倍ほど早いことがわかりました。 実は、複合インデックスは複合インデックスの先頭から順にwhere句に利用されていないと有効に働きません
範囲比較と等値比較の場合はマルチインデックスの定義順序が重要になる
上記の例は等値比較なので、範囲比較も織り交ぜて検証してみます。
以下のような従業員テーブル(約30万レコード)があると仮定します

select * from employees where first_name = "Georgi" and "1988-01-01" < hire_date and hire_date < "1990-12-31"
上記のクエリを実行する場合に、以下の2パターンで以下のSQLを実行した際の実行完了時間を比較しました。
- 複合インデックス(
first_name,hire_date)が貼られている場合 - 複合インデックス(
hire_date,first_name)が貼られている場合
結果は以下のとおりです。
- 複合インデックス(
first_name,hire_date)が貼られている場合- 3.2ms
- 複合インデックス(
hire_date,first_name)が貼られている場合- 88.7ms
複合インデックス(first_name, hire_date)が貼られている場合の方が15倍程度早い
これは、Bツリーインデックスのたどり方による差異が出ています
(first_name, hire_date)の場合、第一カラムが等置比較のため範囲が絞られ、
その後は第二カラムが範囲比較されているので、リーフノードを範囲外になるまで舐めていきその範囲全てのデータを取得します。

対して(hire_date, first_name)の場合、第一カラムが範囲比較のため範囲が絞られ、
その後は第二カラムが等値比較されているので、リーフノードを決まった範囲まで舐めていき、等値比較が一致しているデータのみを取得します。
この方法は、前者の場合に比べて不要なリーフノードにまでアクセスしているため、アクセス性能が遅いです。

したがって、等値比較と範囲比較が含まれるクエリに対してインデックスを貼る場合には、 1.等値比較の対象カラム, 2.範囲比較の対象カラム の順に複合インデックスを定義すると処理が早くなる場合があるということでした。
:::warning
ただし、今回の結果は、first_name および hire_date のカーディナリティやクエリの選択率に依存した結果です。
場合(例えばfirst_nameの選択率に比べてhire_dateの選択率がとても低い場合など)によっては結果が逆転する可能性も普通ににあります。のであくまで参考程度に考えてください
:::
どういうときにインデックスが有効にならないか
上記の検証とは逆に、インデックスが効くと思われているが効いてないような場面を検証してみました。
IS NULL
IS NULL書籍には効かないと書いてありましたが最近はindexが効くらしいです。
念のため、先ほども出た給与管理テーブルにて、100件ほどsalaryカラムをnullにした後、 以下の2パターンで以下のSQLを実行した際の実行完了時間を比較しました。
- インデックス(
salary)有り - インデックス(
salary)無し
select * from salaries where salary IS NULL
結果は以下のとおりです
- インデックス(
salary)有り- 40.9ms
- インデックス(
salary)無し- 476ms
インデックスありの方が10倍程度早い
IS NULLでもインデックスは有効に効くことがわかりました
中間一致検索・後方一致検索
先ほども出てきた従業員テーブルにインデックス(first_name)を貼った場合に、以下の3パターンで検索処理をかけた場合の実行時間を比較しました。
- 先頭一致(
first_name LIKE "Geor%") - 中間一致(
first_name LIKE "%eor%") - 後方一致 (
first_name LIKE "%eori")
結果は以下のとおりです
- 先頭一致(
first_name LIKE "Geor%")- 5.5ms
- 中間一致(
first_name LIKE "%eor%")- *38ms
- 後方一致 (
first_name LIKE "%eori")- 86.3ms
先頭一致の場合は他と比較して6倍以上早い また、実行計画を見ると先頭一致の場合のみインデックスが効いていることがわかりました。 仕組みとしては、Bツリーインデックスは辞書順に並び替えているので、先頭の文字で絞り込めないとどこのリーフノードにも目的のデータが存在しているかもしれないので全てのデータにアクセスする必要が出てくるためです
カラムに対して計算がかかっている時
以下の2つは条件の意味としては同一だが、実行時間が大きく異なります。
select * from employees where hire_date < DATE_ADD("1985-06-15", INTERVAL 10 DAY);- 4.9ms
select * from employees where DATE_SUB(hire_date, INTERVAL 10 DAY) < "1985-06-15"- 9.1ms
カラムに対して計算がかかっている場合に比べ、定数に対して計算がかかっている場合は約2倍早い 実行計画を見ると、定数に対して計算がかかっている場合のみインデックスが効いています
テーブルの大部分を検索したい場合
冒頭で紹介した通り、選択率は現代のDBでは5~10%程度未満になる条件が良いとされています
そうでない場合(選択率が5~10%以上ある場合)はフルスキャンの方が早い可能性が高いです。
以下の図は、「検索するレコードの割合によって、索引スキャン、全表スキャンの処理速度がどのように変わっていくかを表した一例」です。このように選択率(検索する割合)が増えてくるとフルスキャンの方が早くなります。
https://www.atmarkit.co.jp/ait/articles/0412/22/news090_2.html
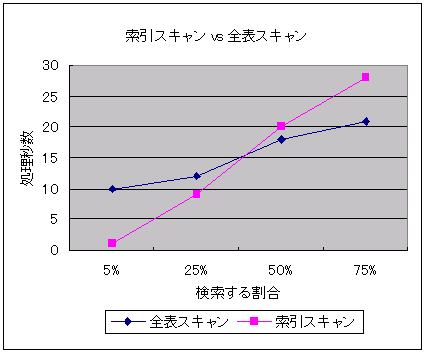
実際に検証してみました。給与テーブルから50%以上の選択率がある以下のSQLを、インデックス(to_date)を強制利用した場合、利用せずにフルスキャンした場合で比較しました。
select * from salaries_copy where to_date > "1998-01-01"
結果は以下のとおりです。
- インデックス(
to_date)を強制利用した場合- 220ms
- 利用せずにフルスキャンした場合
- 39.9ms
フルスキャンの方が8倍ほど早い
フルスキャンの方が早いというのはあまり直感的ではありませんが、実はインデックスによるアクセスは意外とコストがかかるようです。
インデックスによるアクセスは以下の3つの処理を行なって実現しています。
(1) ツリーを走査し、 (2) リーフノードチェーンをたどり (3) テーブルからデータを読み出す
(2)と(3)は行数分だけ繰り返し処理が行われます。フルスキャンの場合は実データ領域からシーケンシャルにデータを複数件まとめて読み出すことができるためです。
オプティマイザについて
インデックス(
to_date)を強制利用した場合
上記の検証では、 インデックス を強制的に使わなければ、フルスキャンをしてしまう。というのも、MySQLのオプティマイザというものがフルスキャン の方が早いと判断したためです。
実際に実行してみないとわからないにもかかわらず、なぜオプティマイザがフルスキャンの方が早いと判断できたかというと、オプティマイザが定期的に統計情報というものを取得しているためです。
統計情報には、各インデックス/テーブルの行数など色々な情報が含まれています。
統計情報は、ある程度のレコード(全体の10%とか)が変更されれば自動的に再計算されたり、手動で再計算させることができます。
https://dev.mysql.com/doc/refman/5.6/en/innodb-parameters.html#sysvar_innodb_stats_auto_recalc
所管
- インデックス、奥が深すぎる
- 「RDBMSの開発者が頑張ってオプティマイザを隠匿化してくれているところを、利用者側がそれを読み解いていく必要があることが残念」みたいなことが書籍で書かれていたが、確かに同意できた。いっその事隠匿化されていない方が読み解くのが簡単なのではないかと感じた
- まだwhereしか触ってなく、joinやgroupbyの時のインデックスの仕組みの調査や検証はまだ未着手。道のりは長いが続けて勉強していきたい
- 昔からあるRDBMSでも、オプティマイザが日々進化していることを感じた(
IS NULLにインデックスが効いていた件)